1.2 운영 체제의 역사
1세대: 진공관
2세대: 트랜지스터 + 배치 시스템
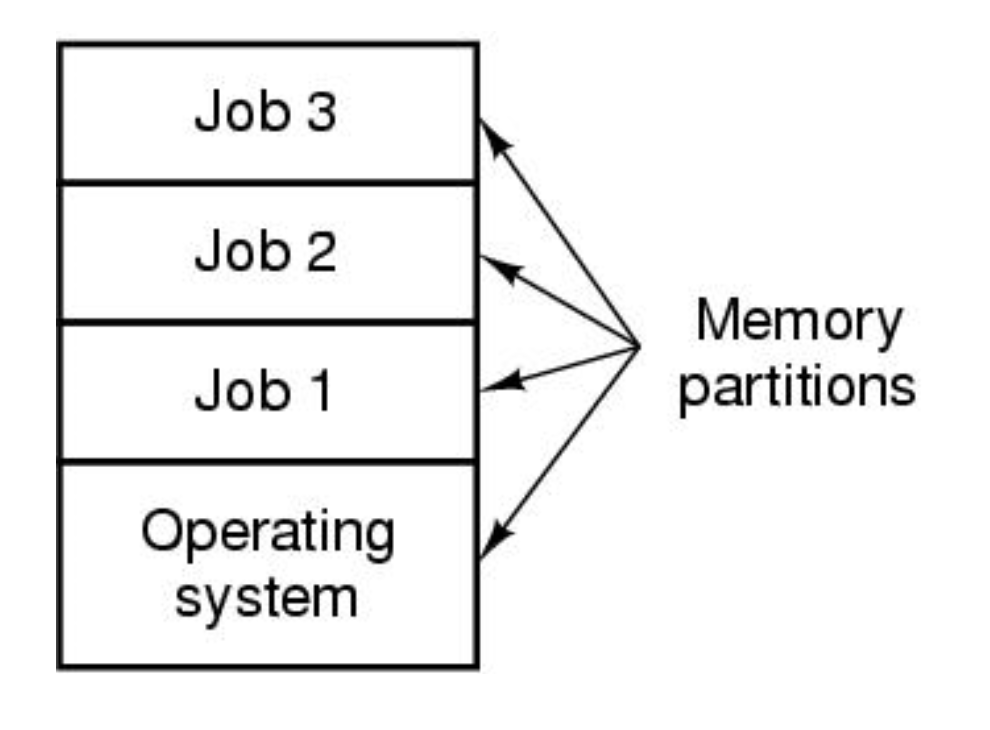
3세대: IC 및 다중 프로그래밍
– CPU는 빠르게 작업하기 때문에 I/O 장치를 기다리고 있음 -> CPU는 유휴 상태이므로 I/O 장치가 작업 1을 처리하는 동안 CPU는 작업 2를 계산할 수 있으며 이 시점에서 다중 프로그래밍이 가능합니다.
– 당시 운영체제에는 MULTICS가 있었지만 보안코드가 많이 포함되어 있어 속도가 매우 느려 상업적으로 성공하지 못했다. 나중에 UNIX로 발전
-pdf11/p12
4세대: 개인용 컴퓨터. CP/M -> DOS -> MS DOS -> GUI …
1.3 하드웨어 점검
CPU는 메모리에서 명령을 받아 실행하고 결과를 메모리로 반환합니다.
모니터나 하드 드라이브와 같은 각 주변 장치는 각 컨트롤러를 통해 연결되며 이러한 장치는 버스를 통해 CPU 및 메모리에 연결됩니다.
컨트롤러에는 메모리, 프로그램 및 코드가 있을 수 있습니다. CPU에서 가져와서 실행하거나 비디오 컨트롤러의 메모리에 명령을 전달할 수 있습니다. SATA 및 NVME와 같은 스토리지는 하드 드라이브 컨트롤러에 있습니다.
버스는 전선입니다. 제어 신호, 주소, 데이터 등이 이를 통해 전송됩니다.
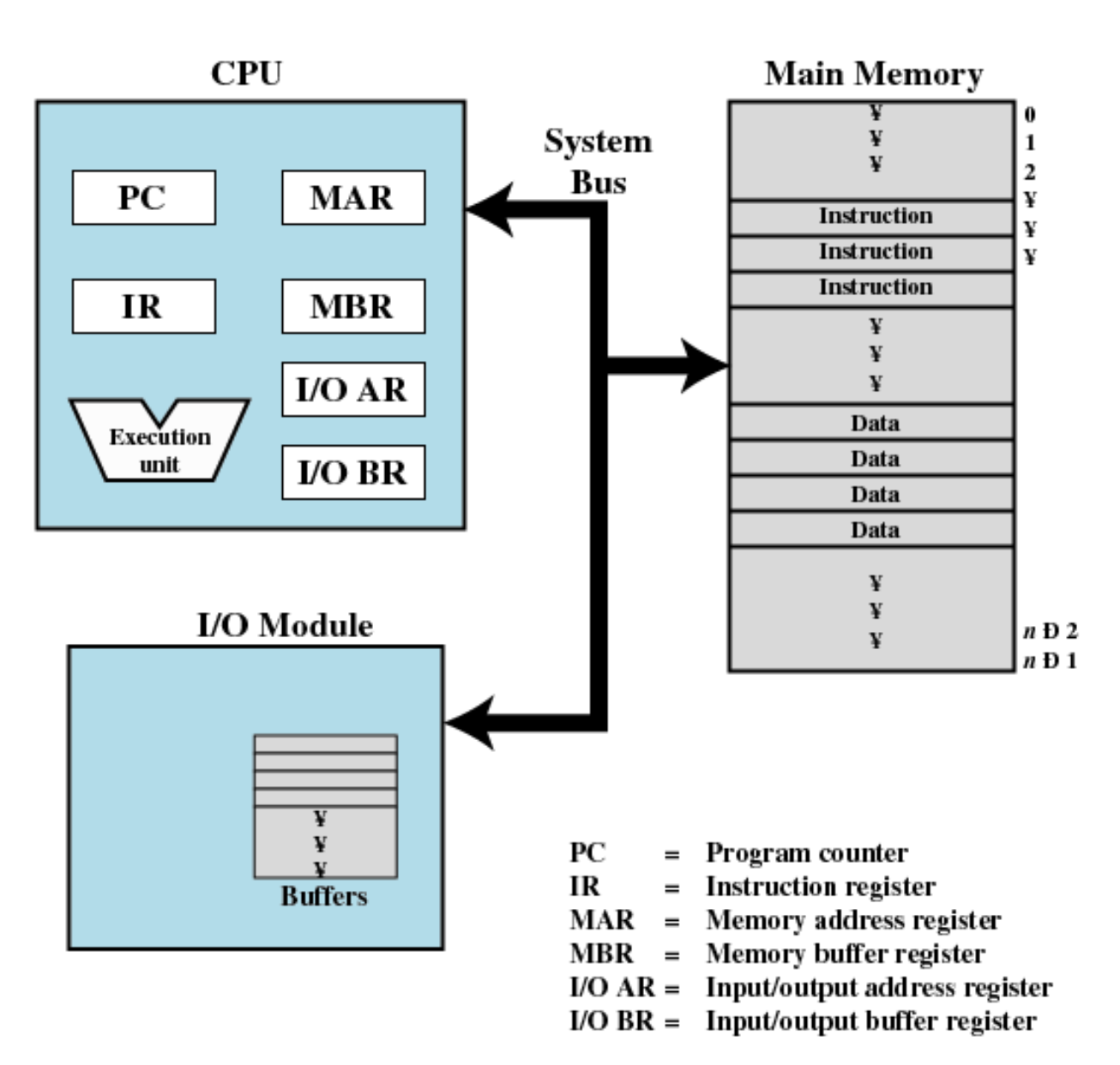
I/O 모듈의 메모리에는 주 메모리와 겹치지 않는 주소가 할당됩니다.
ex) 10번은 매번 주소가 다릅니다.
프로세서 레지스터는 사용자에게 보이고 보이지 않습니다(운영 체제에서 사용됨).
명령이나 데이터를 가져오기 위해 메모리에 액세스하는 것은 명령을 실행하는 것보다 훨씬 오래 걸리기 때문에 모든 CPU에는 중요한 변수나 결과를 임시로 저장할 수 있는 레지스터가 있습니다.
데이터, 주소, 인덱스, 세그먼트 포인터 및 스택 포인터(메모리에서 현재 스택의 맨 위를 가리킴)가 사용자에게 표시됩니다.
특수 또는 사용자가 볼 수 없는 레지스터에는 프로그램 카운터(인출할 다음 명령의 메모리 주소 포함), IR(명령 레지스터), PSW(프로그램 상태 단어), 비교 작업에 의해 설정된 조건 코드 비트, CPU 우선 순위, 모드, es는 다른 제어 비트입니다).
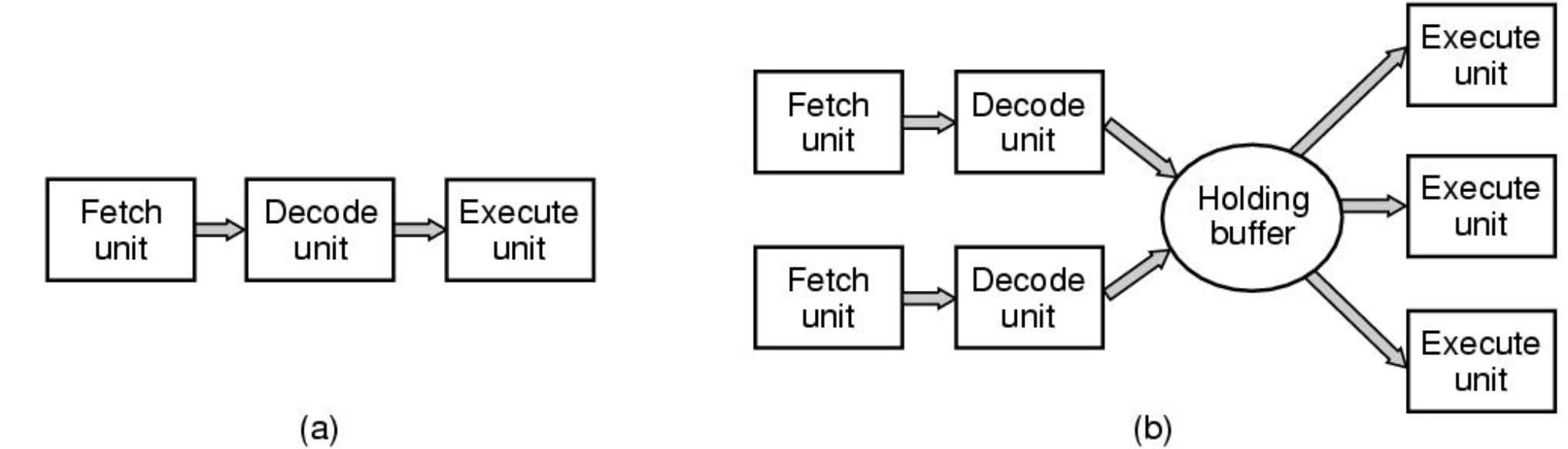
파이프라이닝: 일을 빨리 끝내자!
기존 CISC 방식은 명령어 길이가 가변적이고 처리가 복잡하다. 파이프라이닝은 이 문제를 효과적으로 해결합니다.
Fetch, Decode 및 Execute의 세 가지 단위로 나뉩니다. 명령을 실행하는 데 필요한 시간이 1/3로 줄어들고 단계 수를 늘릴 수 있습니다.
단점은 더 많은 저항과 트랜지스터가 사용되어 열이 발생한다는 것입니다. 그리고 분기 명령이 있는 경우 이전에 처리된 모든 명령을 폐기해야 합니다.
그래서 리스크가 있고, 모바일은 7단계, 데스크탑은 11단계로 구성되어 있습니다.
수퍼스칼라 CPU는 이를 홀딩 버퍼에 수집하고 동시에 실행하여 가능한 한 많이 동시에 실행합니다.
더 빠르게 실행하려면 멀티스레딩 및 하이퍼스레딩(Intel)을 사용하십시오.
CPU가 두 개의 서로 다른 스레드 상태를 갖고 나노초 단위로 동시에 앞뒤로 두 가지 작업을 수행할 수 있습니다.
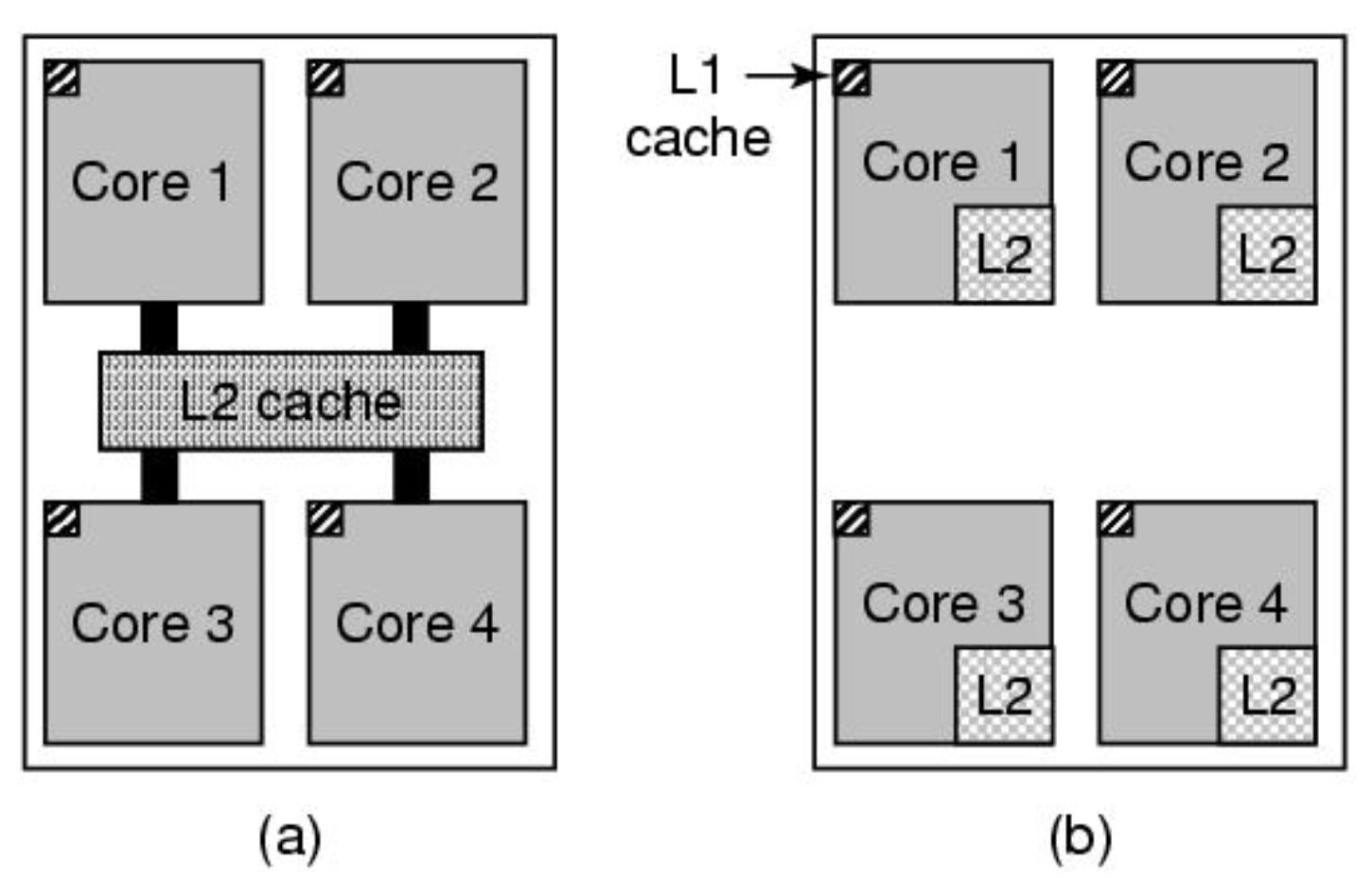
여기서는 더 빠르고 멀티 코어를 사용하고 싶습니다. b는 편리하지만 속도 저하 문제가 있으므로 한 가지 방법을 사용합니다. 요즘에는 l2가 내부이고 l3이 공유됩니다.
중단: CPU가 프로그램을 실행하는 동안 입출력 하드웨어와 같은 장치에서 예외가 발생하면 예외가 발생하여 처리해야 할 때 처리할 수 있도록 CPU에 알려줍니다. 첫 번째적으로 처리해야 할 일이 발생하면 처리하여 원래 작업으로 복원합니다.
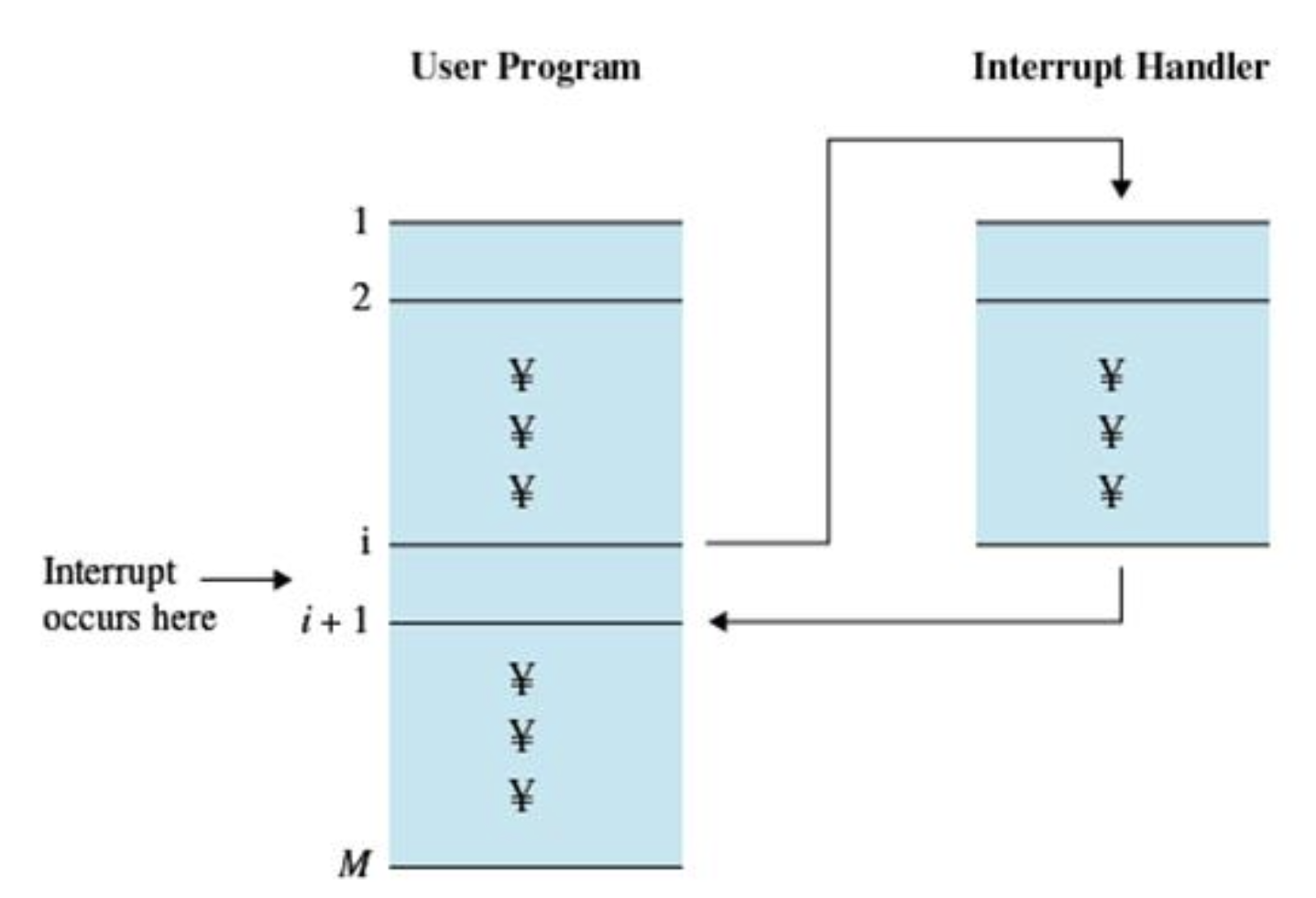
i 번째 명령어 실행 중 인터럽트 발생 -> 버스에 인터럽트 라인 존재 (또는 인터럽트 컨트롤러 존재) -> i 번째 명령어까지 실행 후 인터럽트 핸들러 실행 -> i+ 1st 명령어 실행
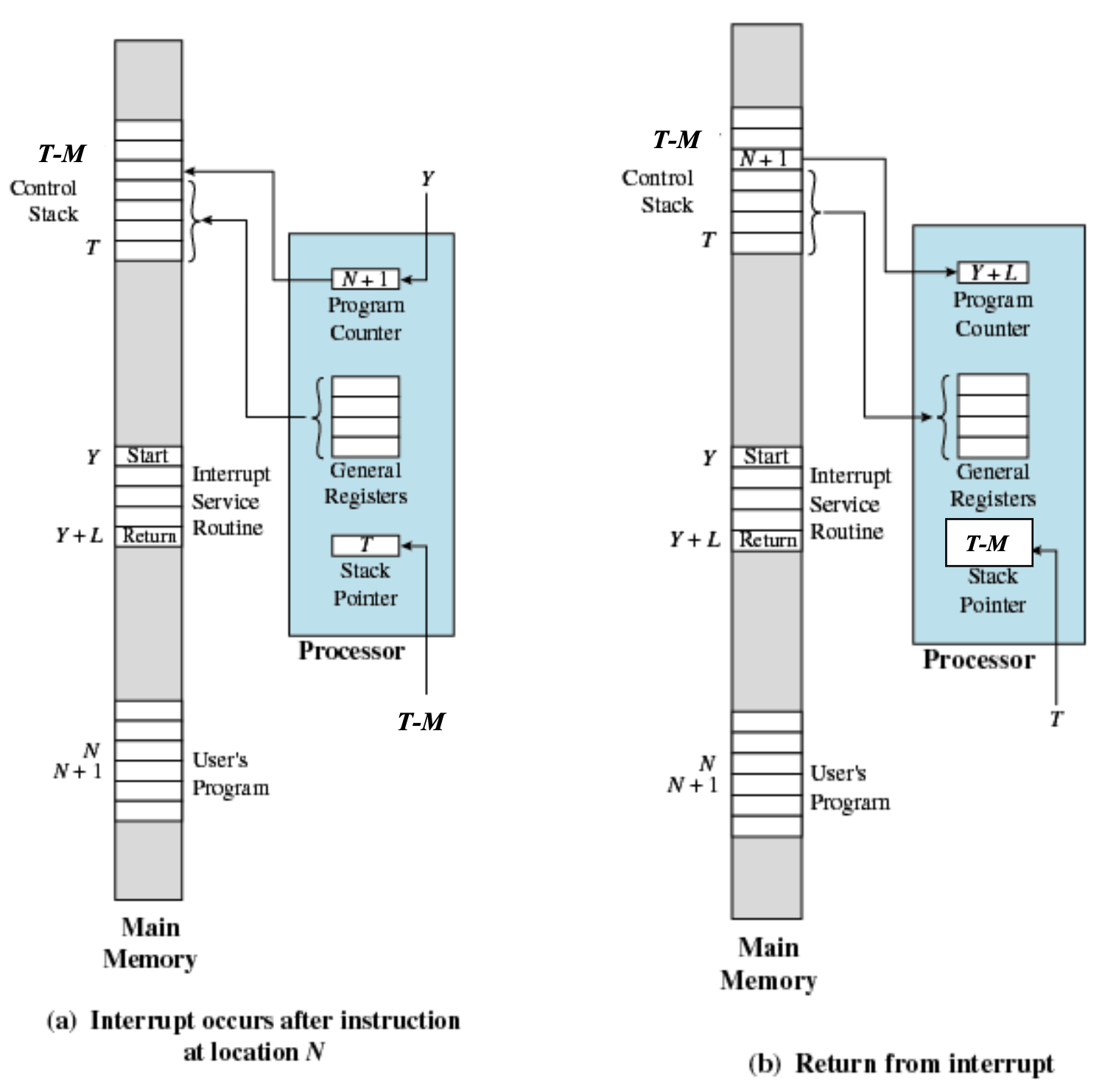
스택은 푸시 팝법안 때문에, 사진 위.
CPU의 일반 레지스터에는 이전 작업이 포함되어 있습니다.. 스택에 저장. 그리고 반송 주소를 설정해야 합니다.. 반환 주소는 현재 프로그램 카운터의 값입니다. n+1~이 되다.
지금 CPU스택 포인터 시간~이 되다. 모든 레지스터가 리셋됨,
프로그램 제어 제이실행(방해하다). 반환 주소가 만족되면 스택에 저장된 레지스터가 원래 레지스터로 반환됩니다.. 스택 포인터 뒤로 티로 감소된다. 스택 반환 주소를 실행하여 원래 프로그램으로 돌아갑니다. n+1두 번째로 이동.
메모리는 레지스터보다 약 10배 느립니다. 그래서 중간에 조금 더 빠르게 작동하는 메모리를 만들었는데 그것이 바로 캐시 메모리입니다.
메인메모리(DRAM)는 카페시터를 사용합니다. 따라서 일정 시간이 지나면 값이 사라지므로 주기적으로 전류를 공급(리프레시)해야 합니다.
캐시 메모리(SRAM)에는 피드백 회로가 있으며 4개의 요소를 사용합니다. 업데이트가 필요하지 않으며 매우 빠릅니다.
블록 크기는 캐시 메모리가 3MB이면 블록 크기가 3KB이면 1000개의 블록이 입력됩니다. 이러한 블록 중 하나는 캐시 라인입니다.
필요한 데이터가 캐시 메모리에 있는 경우를 캐시 적중이라고 합니다.
문제는 항목이 캐시 메모리로 가져와야 할 때 주소가 거기에 있지만 데이터를 주 메모리로 가져오면 동일한 주소를 갖게 된다는 것입니다. 데이터가 변경되면 시스템 메모리(메인 메모리)의 데이터와 다른 더티 메모리를 처리하는 등의 문제가 발생합니다(write back: 일정 시간 후 즉시, write through: 즉시).
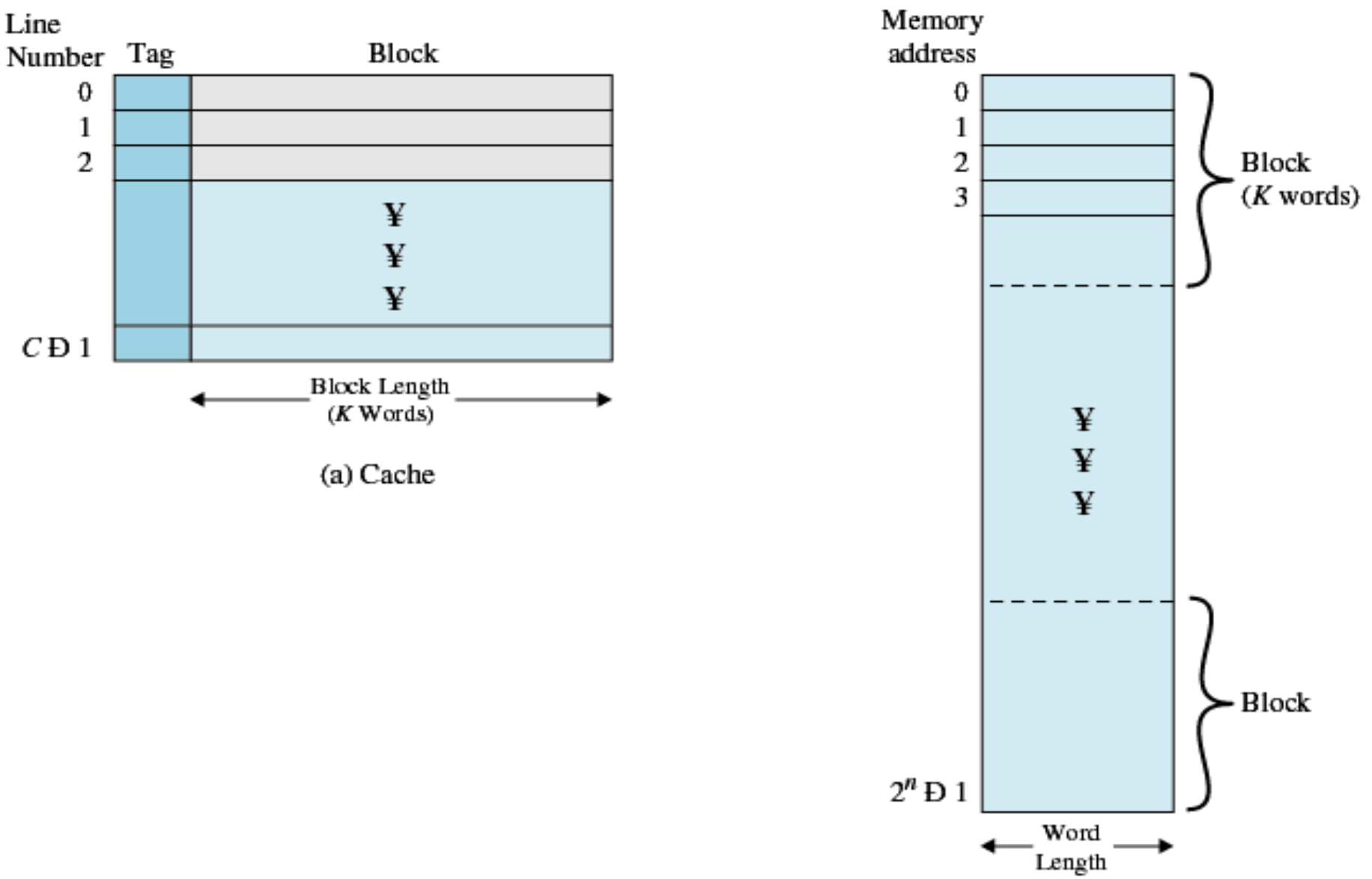
CPU가 한 번에 처리할 수 있는 데이터의 단위는 워드 길이입니다. 이러한 워드 중 일부는 함께 그룹화되어 블록이라고 하며 실제 데이터가 저장되는 영역 왼쪽에 태그(주소)가 있고 0에서 c-1까지 태그와 블록 쌍이 있습니다.
이 데이터를 매핑하는 세 가지 방법이 있습니다.
완전 연관 매핑: 8자리 중 마지막 3자리를 제외하고 태그로 00000을 가집니다.
CPU는 캐시 메모리를 찾고 이전 태그 부분을 비교합니다. 각 메모리 라인의 라벨 옆에 비교회로를 배치하고 결과가 있으면 뒷부분의 주소와 데이터를 CPU로 전달한다.
이 시점에서 Cache-Kiss가 없고 캐시의 모든 메모리가 이미 사용된 경우 사용 가능성이 없는 메모리를 제거하고 삽입합니다. 가장 오래된 참조 데이터는 일반적으로 폐기됩니다(LRU 방법). 이때 캐시 메모리의 데이터가 변경되면 메인 메모리에 기록됩니다. 비교회로가 비싸서 비용이 많이 든다.
직접 배정: 해결책. 캐시 메모리에 저장될 위치는 인덱스에 따라 결정됩니다. 새로운 데이터가 도착하면 같은 인덱스의 데이터를 버리고 삽입한다. 문제는 자주 참조되는 데이터가 같은 인덱스에 있으면 이런 과정이 반복(핑퐁 현상) -> 성능 저하라는 점이다.
연관 매핑 설정: 위의 두 가지를 결합합니다. 저희 PC에서는 보통 8핀 커넥터로 사용합니다. 비교 회로에는 가능한 한 많은 가능성이 있습니다. 이 방법은 일반적으로 CPU에서 사용됩니다.
캐시 메모리 성능: 메인 메모리 속도의 10배.
메모리 액세스 시간: 적중률 * 캐시 메모리 + (1 – 적중률) * (캐시 + 메인). 어쨌든 효율적입니다. 캐시 메모리는 메모리와 디스크, 네트워크 시스템과 웹 서버 사이에서 웹 캐시를 대신하여 사용됩니다.
캐시 메모리의 효과는 지역성을 기반으로 합니다. Locality는 시간적/공간적 요소를 가진다.
루프가 돌면서 계속 참조하지만 캐싱하면 빠르게 계속 사용할 수 있습니다.
공간적 부분(특정 지역성)에서 기억의 특정 부분에 대한 참조는 그 주변을 참조하기도 합니다. 배열의 특정 부분을 변경하고 싶다면 요약하는 것과 같은 방식으로 참조하세요.
작업 집합: 일반적으로 사용되는 데이터 모음을 작업 집합이라고 합니다. 잘 대처하면 적중률을 높일 수 있지만 현실적으로 어렵다.
디스크.
대부분 플래시 메모리를 사용하지만 과거에는 하드디스크를 주로 사용했기 때문에 운영 체제에 디스크 관련 콘텐츠가 많다.
원은 개별 트랙으로 나뉘고 다시 섹터라고 하는 세그먼트로 나뉩니다. 디스크 헤드를 원하는 트랙의 위치로 이동시켜 데이터를 읽어들인다 헤드가 연결되어 있어 헤드가 움직이자마자 특정 트랙으로 이동하고 헤드는 다른 면에서도 같은 위치로 이동한다. 이는 실린더와 관련된 트랙 세트를 정의합니다.
I/O 장치(디스크 포함): 디스크에서 메모리로 정보를 가져오는 방법에는 세 가지가 있습니다.
현재 문이 실행되고 다음 문이 도착하면 인터럽트가 발생하여 핸들러가 실행되고 다음 프로그램이 실행됩니다.
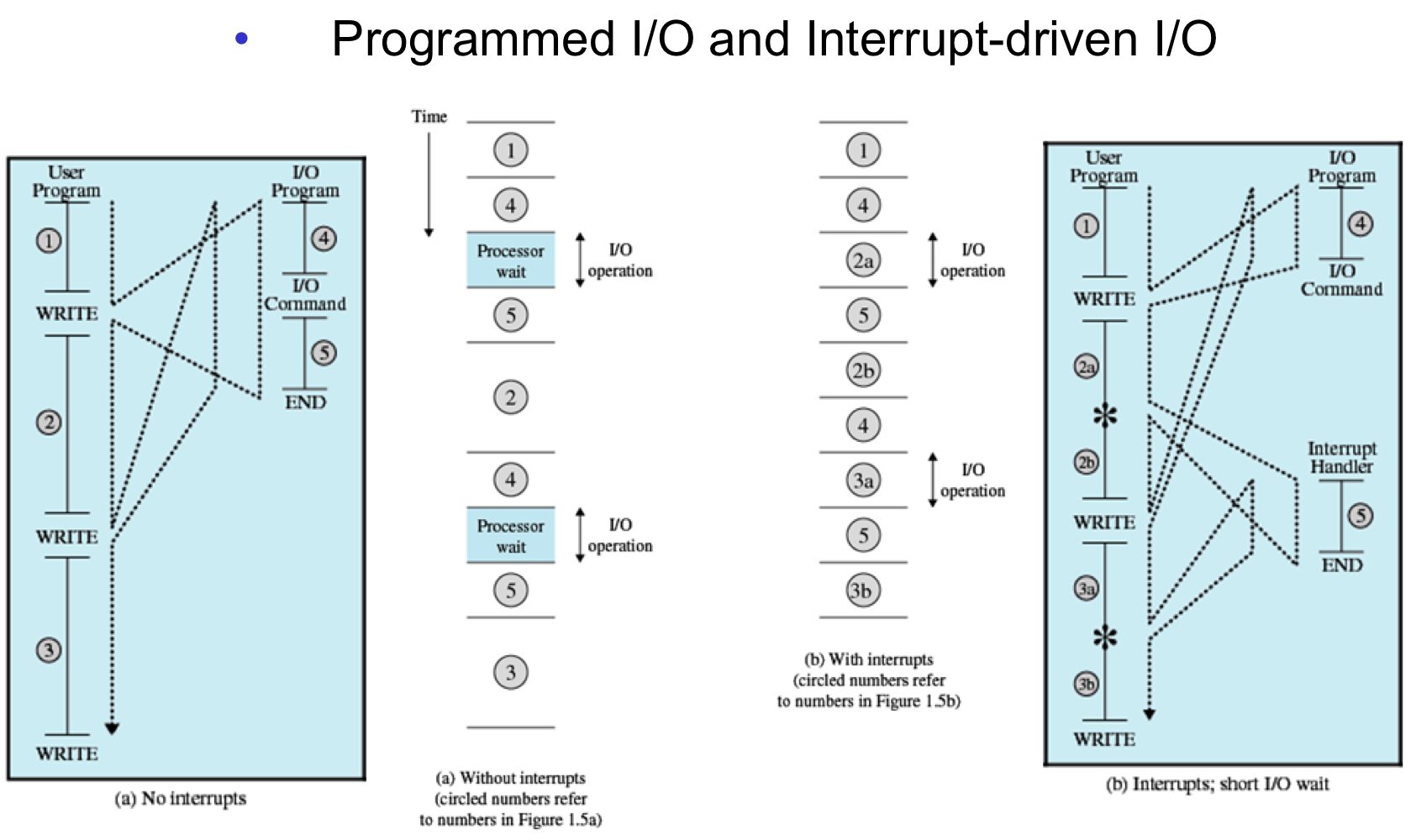
왼쪽 길은 계속해서 휴식을 취합니다. 올바른 방법은 io 프로그램을 두 부분으로 분할하여 작동합니다.
—– 매우 절박해서 모든 데이터를 잃어버리고 심신이 쇠약해진 상태…
올바른 방법은 좋아 보이지만 현재는 그렇지 않습니다. 왜? io 명령은 느리고 CPU는 빠르기 때문에 여전히 기다려야 합니다.
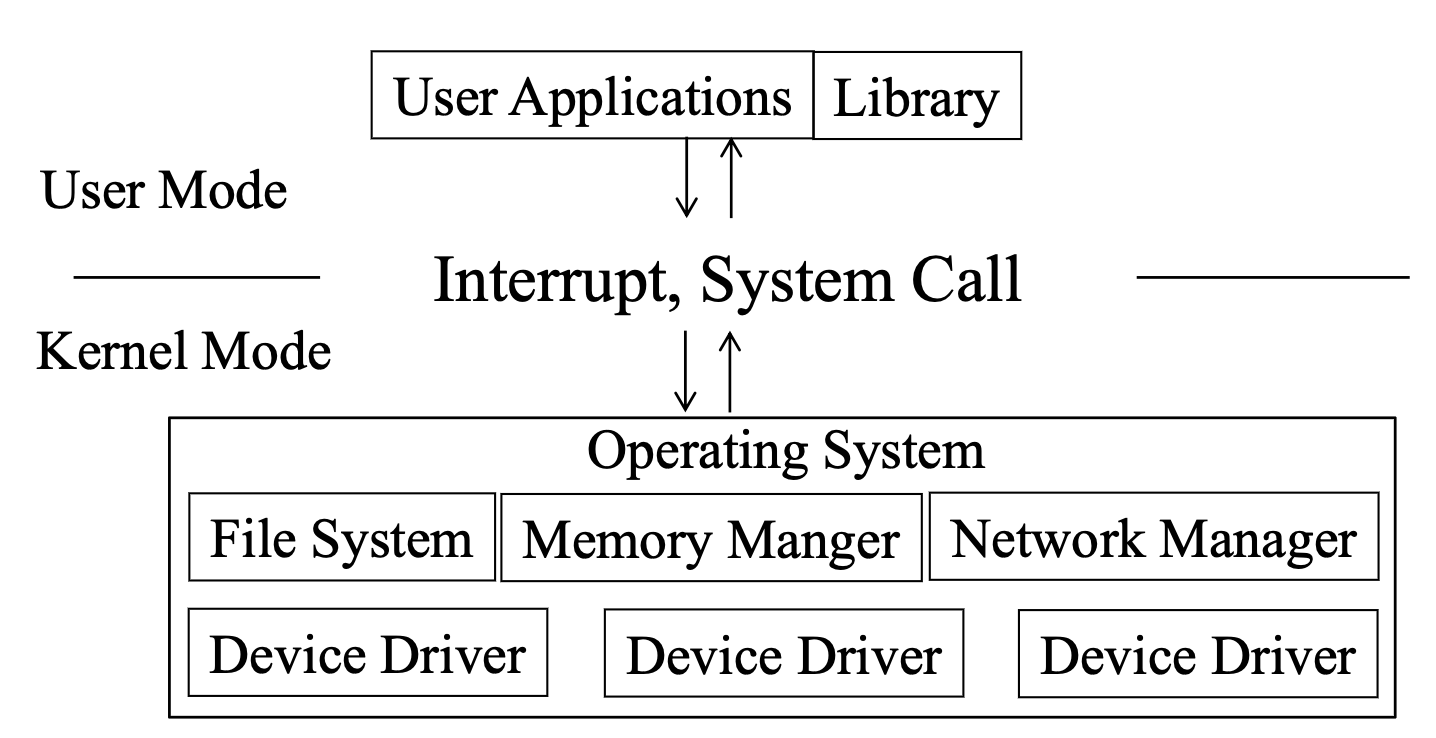
CPU는 두 가지 주요 모드를 지원합니다.
1. 운영 체제는 사용자 프로그램에 연결되어 있습니다. 현재 서로에게 io를 요청하는 것은 복잡하므로 CPU는 두 개의 모듈을 생성하여 이를 지원합니다.
사용자 프로그램은 사용자 모드에서 실행되고 운영 체제는 커널 모드에서 실행됩니다. 권한 있는 명령은 커널 모드에서만 실행할 수 있습니다.
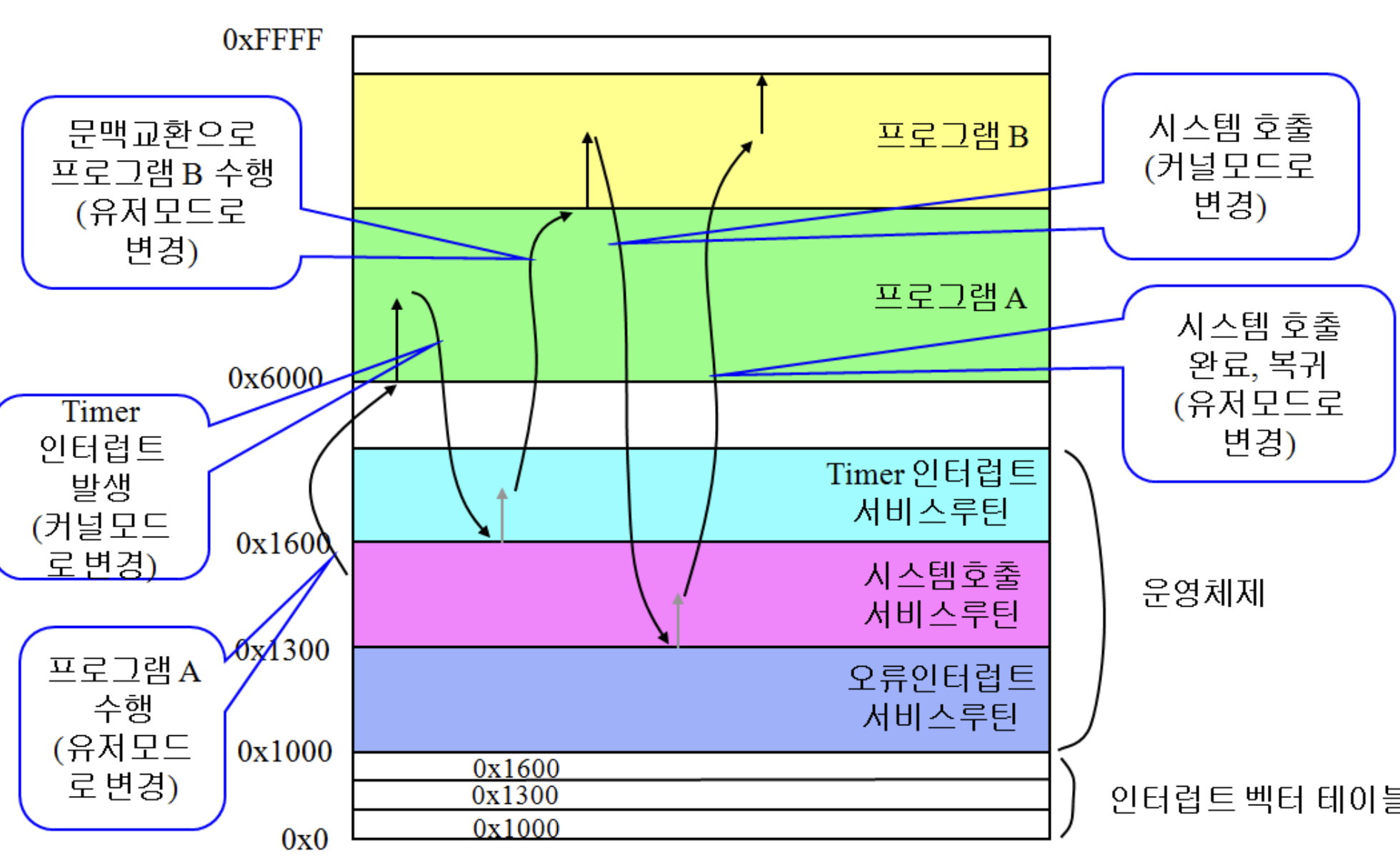
보다 구체적으로 말하면, 타이머 인터럽트에서 시간 관련 정보를 업데이트하고 마지막에 스케줄링하면서 메모리를 끝까지 따릅니다.
타이머가 중단될 때마다 프로세스가 시간 초과되었는지 여부를 확인하고 다음에 실행할 작업을 결정합니다. 이것이 스케줄러의 역할이자 타이머 인터럽트 서비스 루틴으로 그림의 b로 돌아갑니다.
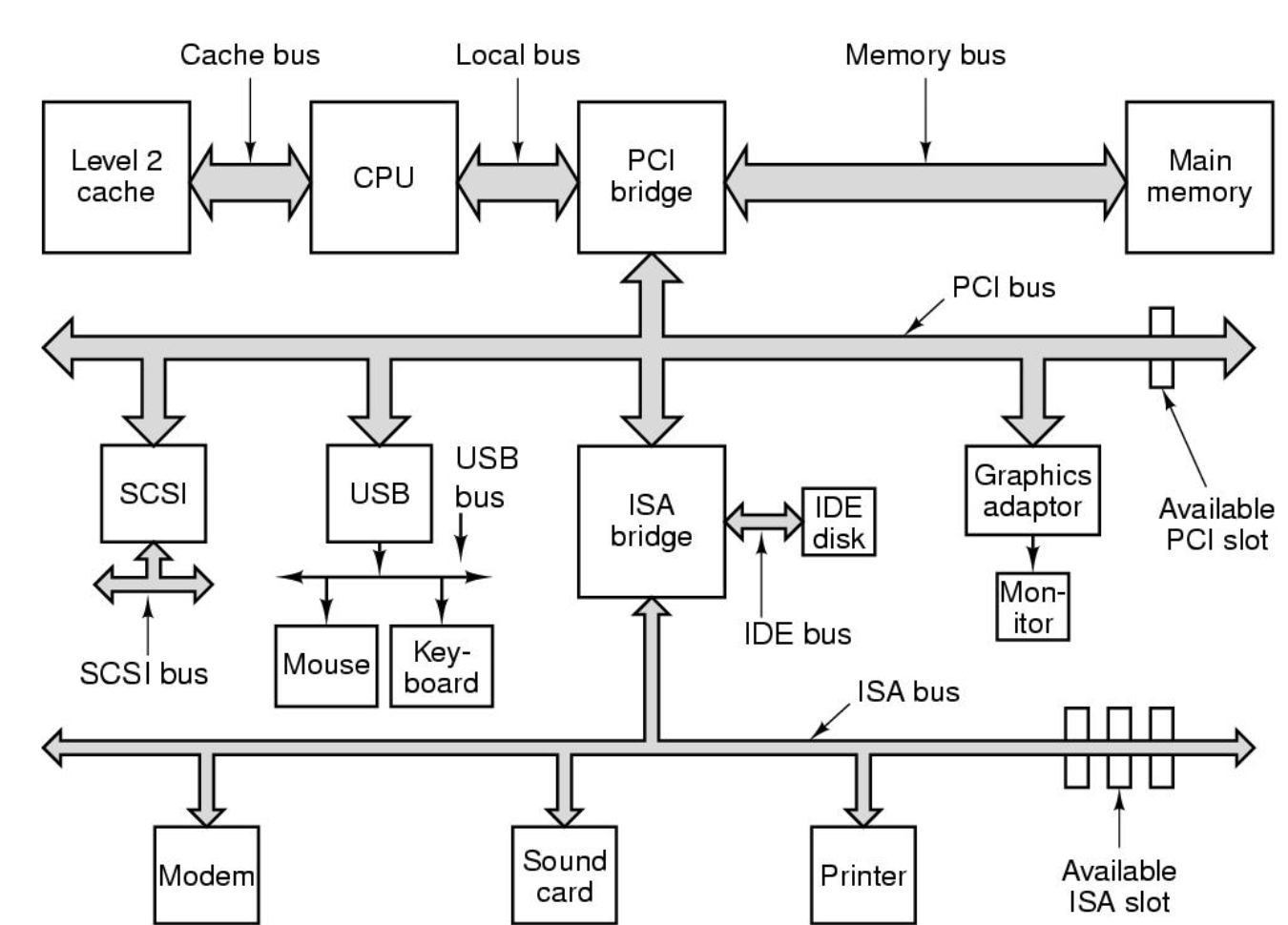
오래 전에는 컴퓨터가 빠르지 않았고 당시에 사용되던 버스가 ISA 버스였습니다.
위 사진과 같이 CPU와 메모리가 바쁜 요즘, 전용 버스를 붙입니다. PCI 버스(주변 장치를 마더보드에 연결)도 있습니다.
다리는 이 모든 것을 연결합니다.
1.4 운영 체제 동물원
운영 체제 유형
메인프레임: 오래된 것.
현재의 모든 운영 체제는 다중 프로세서 운영 체제입니다. 추세 또는 성능 압박이 심합니다.
PC 운영 체제: Windows, Mac OS, Linux
핸드헬드(ios 및). 임베디드, 센서: Linux
실시간: 다른 문제
스마트 카드: 학생증의 칩 운영체제 같은 것을 의미합니다.
1.5 운영 체제 개념
운영 체제 개념
프로세스: 중요
파일: 우리가 알고 있는 파일뿐만 아니라 과거에 포함되었던 주변 장치(장치 파일)
Ontogeny는 계통학을 요약합니다. 이전 운영 체제에는 이 기능이 필요하지 않았습니다(오래된 폴더형 전화기를 생각해 보십시오).
운영 체제가 한 영역에서 발전함에 따라 다른 영역의 운영 체제도 발전합니다. 오래된 분산 시스템은 무용지물로 여겨졌지만 요즘에는 클라우드 컴퓨팅이 각광을 받고 있습니다.
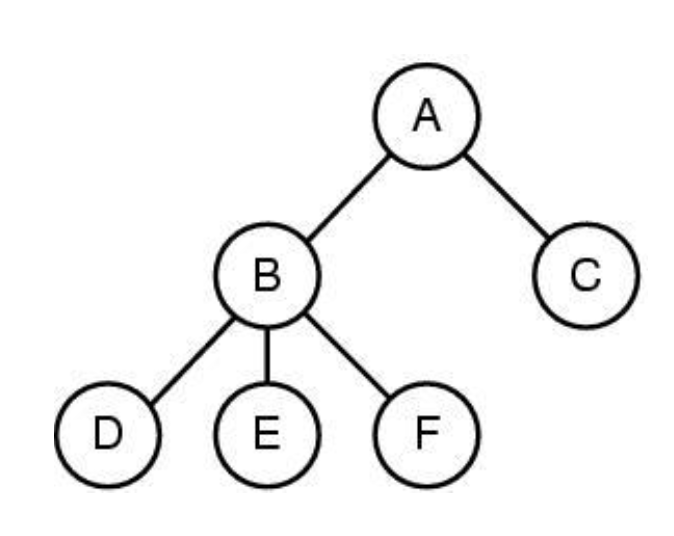
그 과정은 혼자 할 수 없습니다. 누군가 실행해야 하고 이미지에서 B라는 쉘 프로그램의 자식이 됩니다. 부모 자식 관계를 가지고
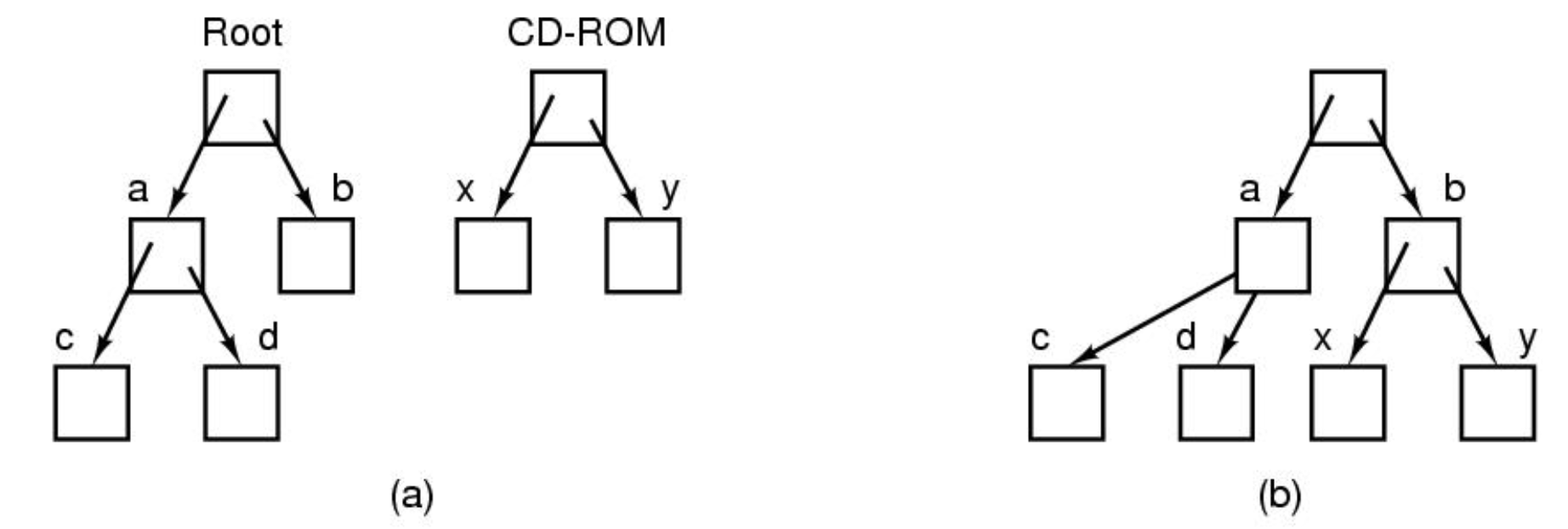
파일 이미지는 과거에는 디렉터리 구분이 없는 단일 수준이었던 파일의 계층적 구조를 보여줍니다.
왼쪽이 윈도우, 오른쪽이 리눅스. Windows에는 각 파일 시스템(파티션)에 대해 별도의 계층 구조가 있습니다.
큰 프로그램에서 여러 프로세스를 사용할 때 파이프는 독립적인 프로세스 간에 데이터를 교환하는 데 사용됩니다.
하드 드라이브에 액세스하지 않고 메모리에서 보내고 받습니다.
시스템 호출: 교과서 참조
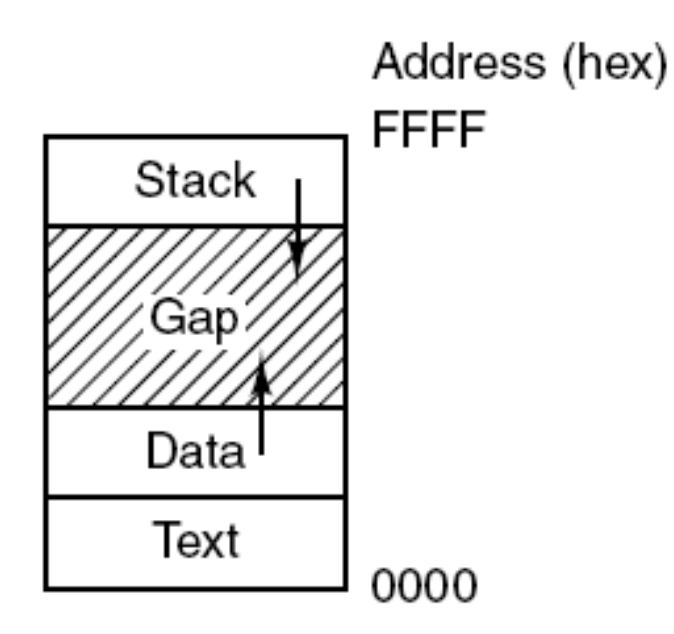
스토리지 레이아웃. 모든 프로그램은 그림과 같은 형식입니다. Gap은 동적 메모리 영역(힙)입니다.
Unix는 파일을 inode로 저장합니다. 각 파일에는 번호가 할당되며 모든 작업은 inode로만 처리할 수 있습니다.
따라서 디렉토리를 생성하고 inode 및 파일 이름 쌍을 생성하고 디렉토리 데이터로 저장합니다. 이것은 계층 구조를 나타냅니다.
링크를 만든 이유 Unix는 많은 사람들이 사용하고 있습니다. 이러한 시분할 운영 체제를 사용하면 여러 사용자가 시스템에 로그온하고 서비스를 전환합니다.
하드 링크는 한쪽에서 삭제하더라도 다른 쪽에서 살아있는 링크입니다.
이를 보완하기 위해 소프트 링크가 있습니다.